Построение линейного тренда. Параметры уравнения тренда
Прямая линия - трендовые значения рентабельности (линейный тренд, построенный по данным фактических значений рентабельности).
Пример 14.6. Построим линейный тренд процентных ставок по кредитам на основе статистических данных, опубликованных в Бюллетене банковской статистики № 4 (47) за 1997 г.
Вторым этапом является поиск значений параметров уравнения. Параметры трендовых моделей определяются с помощью системы нормальных уравнений . В случае применения линейного тренда используют следующую систему уравнений, которую решают способом наименьших квадратов
Пример 14.7. Предполагая наличие циклических колебаний , проведем гармонический анализ динамики отклонений от линейного тренда данных о ставках по кредитам (у, - у,).
Линейный тренд хорошо отражает тенденцию изменений при действии множества разнообразных факторов, изменяющихся различным образом по разным закономерностям. Равнодействующая этих факторов при взаимопогашении особенностей отдельных фак-
При b = 1 имеем линейный тренд, b = 2 - параболический и т.п. Степенная форма - гибкая, пригодная для отображения изменений с разной мерой пропорциональности изменений во времени. Жестким условием является обязательное прохождение через начало координат при t = 0, у = 0. Можно усложнить форму тренда у = а + th или у = а + th, но эти уравнения нельзя логарифмировать, трудно вычислять параметры, и они крайне редко применяются.
Для линейного тренда нормальные уравнения МНК имеют вид
В формуле (9.33) суммирование от = -(л-1) 2до/ = (л- 1) 2 в целом формула (9.33) аналогична формуле для линейного тренда (9.29).
Согласно формуле (9.29) параметры линейного тренда равны а = 1894/11 = 172,2 ц/га 2>Л= 486/110 = 4,418 ц/га. Уравнение линейного тренда имеет вид у = 172,2 + 4,418/, где (= 0 в 1987 г. Это означает, что средний фактический и выравненный уровень, отнесенный к середине периода, т.е. к 1991 г., равен 172 ц с 1 га, а среднегодовой прирост составляет 4,418 ц/га в год.
Поскольку по данным табл. 9.4, уже было установлено, что тренд имеет линейную форму , проводим расчет среднегодового абсолютного прироста , т. е. параметра Ъ уравнения линейного тренда сколь-
Колеблемость умеренная, не сильная. Для сравнения приводим показатели (без расчета) по колебаниям урожайности картофеля, данные таблиц 9.1 и 9.5 - отклонение от линейного тренда s(t) = 14,38 ц с 1 га, v(t) = 8,35%.
Для получения достаточно надежных границ прогноза положения тренда, скажем, с вероятностью 0,9 того, что ошибка будет не более указанной, следует среднюю ошибку умножить на величину /-критерия Стьюдента при указанной вероятности (или значимости 1 - 0,9 = 0,1) и при числе степеней свободы , равном, для линейного тренда, N- 2, т. е. 15. Эта величина равна 1,753. Получаем предельную с данной вероятностью ошибку
Другим приемом измерения корреляции в рядах динамики может служить корреляция между теми из цепных показателей рядов, которые являются константами их трендов. При линейных трендах - это цепные абсолютные приросты . Вычислив их по исходным рядам динамики (axl, ayi), находим коэффициент корреляции между абсолютными изменениями по формуле (9.52) или, что более точно, по формуле (9.51), так как средние изменения не равны нулю в отличие от средних отклонений от трендов. Допустимость данного способа основана на том, что разность между соседними уровнями в основном состоит из колебаний, а доля тренда в них невелика, следовательно, искажение корреляции от тренда очень большое при кумулятивном эффекте на протяжении длительного периода , весьма мало - за каждый год в отдельности. Однако нужно помнить, что это справедливо лишь для рядов с с-показателем, существенно меньшим единицы. В нашем примере для ряда урожайности с-по-казатель равен 0,144, для себестоимости он равен 0,350. Коэффициент корреляции цепных абсолютных изменений составил 0,928, что очень близко к коэффициенту корреляции отклонений от трендов.
В одном из предыдущих примеров мы рассмотрели прогноз по объему производства за два месяца некой компании из Дублина. Были получены оценки на 1997 год, при этом использовался линейный тренд и метод сложения . Прогнозные значения даны в тоннах
Значения k для оценки доверительных интервалов прогноза относительно линейного тренда с вероятностью 0,8
Адаптивное моделирование линейного тренда с помощью экспоненциальных скользящих средних.
Алгоритм вычисления параметров линейного тренда
Вычислить в первом приближении параметры линейного тренда
Определить окончательные значения параметров линейного тренда
ЕМА ошибок могут ухудшить качество прогноза. В этом случае при расчете параметров линейного тренда нужно остановиться на шаге 2 этого алгоритма.
LN - линейный тренд, сезонность не учитывается
Если считать, что изменения цен, вопреки соображениям эффективности на продолжительных отрезках времени, определяются многочисленными и часто нелинейными обратными связями , то на основе теории хаоса можно построить улучшенные модели, описывающие влияние прошлого на настоящее (см. -). Драматические обвалы рынка при отсутствии существенных изменений информации, резкие изменения условий доступа и сроков при пересечении компанией какого-то невидимого порога в кредитной сфере - все это проявления нелинейности. Реальное поведение финансовых рынков , скорее, противоречит правилам обращения линейных трендов, чем подтверждает их.
Метод последовательных разностей заключается в следующем если ряд содержит линейный тренд, тогда исходные данные заменяются первыми разностями
Значения Лу не имеют четко выраженной тенденции, они варьируют вокруг среднего уровня, что означает наличие в ряде динамики линейного тренда (линейной тенденции). Аналогичный вывод можно сделать и по ряду х абсолютные приросты не имеют систематической направленности, они примерно стабильны, а следовательно, ряд характеризуется линейной тенденцией.
Это привело к идее измерения корреляции не самих уровней х, иу а первых разностей Дх, = х, - , 6у, - у, - у,.., (при линейных трендах). В общем случае было признано необходимым коррелировать отклонения от трендов (за вычетом циклической компоненты) Еу -у, - %, Ех = х, - %, (у,% - тренды временных рядов).
На графике рис. 5.3 наглядно видно наличие возрастающей тенденции. Возможно существование линейного тренда.
Параметры линейного тренда можно интерпретировать так а - начальный уровень временного ряда в момент времени t = 0 b - средний за период абсолютный прирост уровней ряда. Применительно к данному временному ряду можно сказать, что темпы роста номинальной месячной заработной платы за 10 месяцев 1999 г. изменялись от уровня 82,66% со средним за месяц абсолютным приростом , равным 4,72 проц. пункта. Расчетные по линейному тренду значения уровней временного ряда определяются двумя способами. Во-первых, можно последовательно подставлять в найденное уравнение тренда значения / = 1, 2,..., л, т.е.
Во-вторых, в соответствии с интерпретацией параметров линейного тренда каждый последующий уровень ряда есть сумма предыдущего уровня и среднего цепного абсолютного прироста, т. е.
Таким образом, начальный уровень ряда в соответствии с уравнением экспоненциального тренда составляет 83,96 (сравните с начальным уровнем 82,66 в линейном тренде), а средний цепной коэффициент роста - 1,046. Следовательно, можно сказать, что
Назначение сервиса . Сервис используется для расчета параметров тренда временного ряда y t онлайн с помощью метода наименьших квадратов (МНК) (см. пример нахождения уравнения тренда), а также способом от условного нуля. Для этого строится система уравнений:a 0 n + a 1 ∑t = ∑y
a 0 ∑t + a 1 ∑t 2 = ∑y t
и таблица следующего вида:
| t | y | t 2 | y 2 | t y | y(t) |
| 1 | |||||
| ... | ... | ... | ... | ... | ... |
| N | |||||
| ИТОГО | ∑ | ∑ | ∑ | ∑ | ∑ |
Инструкция . Укажите количество данных (количество строк). Полученное решение сохраняется в файле Word и Excel .
Тенденция временного ряда характеризует совокупность факторов, оказывающих долговременное влияние и формирующих общую динамику изучаемого показателя.
Способ отсчета времени от условного начала
Для определения параметров математической функции при анализе тренда в рядах динамики используется способ отсчета времени от условного начала. Он основан на обозначении в ряду динамики показаний времени таким образом, чтобы ∑t i . При этом в ряду динамики с нечетным числом уровней порядковый номер уровня, находящегося в середине ряда, обозначают через нулевое значение и принимают его за условное начало отсчета времени с интервалом +1 всех последующих уровней и –1 всех предыдущих уровней. Например, при обозначения времени будут: –2, –1, 0, +1, +2 . При четном числе уровней порядковые номера верхней половины ряда (от середины) обозначаются числами: –1, –3, –5 , а нижней половины ряда обозначаются +1, +3, +5 .Пример . Статистическое изучение динамики численности населения.
- С помощью цепных, базисных, средних показателей динамики оцените изменение численности, запишите выводы.
- С помощью метода аналитического выравнивания (по прямой и параболе, определив коэффициенты с помощью МНК) выявите основную тенденцию в развитии явления (численность населения Республики Коми). Оцените качество полученных моделей с помощью ошибок и коэффициентов аппроксимации.
- Определите коэффициенты линейного и параболического трендов с помощью средств «Мастера диаграмм». Дайте точечный и интервальный прогнозы численности на 2010 г. Запишите выводы.
| 1990 | 1996 | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 |
| 1249 | 1133 | 1043 | 1030 | 1016 | 1005 | 996 | 985 | 975 | 968 |
а) Линейное уравнение тренда имеет вид y = bt + a
1. Находим параметры уравнения методом наименьших квадратов
. Используем способ отсчета времени от условного начала.
Система уравнений МНК для линейного тренда имеет вид:
a 0 n + a 1 ∑t = ∑y
a 0 ∑t + a 1 ∑t 2 = ∑y t
| t | y | t 2 | y 2 | t y |
| -9 | 1249 | 81 | 1560001 | -11241 |
| -7 | 1133 | 49 | 1283689 | -7931 |
| -5 | 1043 | 25 | 1087849 | -5215 |
| -3 | 1030 | 9 | 1060900 | -3090 |
| -1 | 1016 | 1 | 1032256 | -1016 |
| 1 | 1005 | 1 | 1010025 | 1005 |
| 3 | 996 | 9 | 992016 | 2988 |
| 5 | 985 | 25 | 970225 | 4925 |
| 7 | 975 | 49 | 950625 | 6825 |
| 9 | 968 | 81 | 937024 | 8712 |
| 0 | 10400 | 330 | 10884610 | -4038 |
Для наших данных система уравнений примет вид:
10a 0 + 0a 1 = 10400
0a 0 + 330a 1 = -4038
Из первого уравнения выражаем а 0 и подставим во второе уравнение
Получаем a 0 = -12.236, a 1 = 1040
Уравнение тренда:
y = -12.236 t + 1040
Оценим качество уравнения тренда с помощью ошибки абсолютной аппроксимации.
Ошибка аппроксимации в пределах 5%-7% свидетельствует о хорошем подборе уравнения тренда к исходным данным.
![]()
б) выравнивание по параболе
Уравнение тренда имеет вид y = at 2 + bt + c
1. Находим параметры уравнения методом наименьших квадратов.
Система уравнений МНК:
a 0 n + a 1 ∑t + a 2 ∑t 2 = ∑y
a 0 ∑t + a 1 ∑t 2 + a 2 ∑t 3 = ∑yt
a 0 ∑t 2 + a 1 ∑t 3 + a 2 ∑t 4 = ∑yt 2
| t | y | t 2 | y 2 | t y | t 3 | t 4 | t 2 y |
| -9 | 1249 | 81 | 1560001 | -11241 | -729 | 6561 | 101169 |
| -7 | 1133 | 49 | 1283689 | -7931 | -343 | 2401 | 55517 |
| -5 | 1043 | 25 | 1087849 | -5215 | -125 | 625 | 26075 |
| -3 | 1030 | 9 | 1060900 | -3090 | -27 | 81 | 9270 |
| -1 | 1016 | 1 | 1032256 | -1016 | -1 | 1 | 1016 |
| 1 | 1005 | 1 | 1010025 | 1005 | 1 | 1 | 1005 |
| 3 | 996 | 9 | 992016 | 2988 | 27 | 81 | 8964 |
| 5 | 985 | 25 | 970225 | 4925 | 125 | 625 | 24625 |
| 7 | 975 | 49 | 950625 | 6825 | 343 | 2401 | 47775 |
| 9 | 968 | 81 | 937024 | 8712 | 729 | 6561 | 78408 |
| 0 | 10400 | 330 | 10884610 | -4038 | 0 | 19338 | 353824 |
Для наших данных система уравнений имеет вид
10a 0 + 0a 1 + 330a 2 = 10400
0a 0 + 330a 1 + 0a 2 = -4038
330a 0 + 0a 1 + 19338a 2 = 353824
Получаем a 0 = 1.258, a 1 = -12.236, a 2 = 998.5
Уравнение тренда:
y = 1.258t 2 -12.236t+998.5
Ошибка аппроксимации для параболического уравнения тренда.
![]()
Поскольку ошибка меньше 7%, то данное уравнение можно использовать в качестве тренда.
Минимальная ошибка аппроксимации при выравнивании по параболе. К тому же коэффициент детерминации R 2 выше чем при линейной. Следовательно, для прогнозирования необходимо использовать уравнение по параболе.
Интервальный прогноз.
Определим среднеквадратическую ошибку прогнозируемого показателя.

m = 1 - количество влияющих факторов в уравнении тренда.
Uy = y n+L ± K
где

L - период упреждения; у n+L - точечный прогноз по модели на (n + L)-й момент времени; n - количество наблюдений во временном ряду; Sy - стандартная ошибка прогнозируемого показателя; T табл - табличное значение критерия Стьюдента для уровня значимости α и для числа степеней свободы, равного n-2
.
По таблице Стьюдента находим Tтабл
T табл (n-m-1;α/2) = (8;0.025) = 2.306
Точечный прогноз, t = 10: y(10) = 1.26*10 2 -12.24*10 + 998.5 = 1001.89 тыс. чел.
1001.89 - 71.13 = 930.76 ; 1001.89 + 71.13 = 1073.02
Интервальный прогноз:
t = 9+1 = 10: (930.76;1073.02)
Покажем пример подробного расчета параметров уравнения тренда на основе следующих данных (см. таблицу) с использованием калькулятора .
Линейное уравнение тренда имеет вид y = at + b.
1. Находим параметры уравнения методом наименьших квадратов
.
Система уравнений МНК:
a 0 n + a 1 ∑t = ∑y
a 0 ∑t + a 1 ∑t 2 = ∑y t
| t | y | t 2 | y 2 | t y | y(t) | (y-y cp) 2 | (y-y(t)) 2 | (t-t p) 2 | (y-y(t)) : y |
| 1 | 17.4 | 1 | 302.76 | 17.4 | 12.26 | 895.01 | 26.47 | 30.25 | 0.3 |
| 2 | 26.9 | 4 | 723.61 | 53.8 | 18.63 | 416.84 | 68.39 | 20.25 | 0.31 |
| 3 | 23 | 9 | 529 | 69 | 25 | 591.3 | 4.02 | 12.25 | 0.0872 |
| 4 | 23.7 | 16 | 561.69 | 94.8 | 31.38 | 557.75 | 58.98 | 6.25 | 0.32 |
| 5 | 27.2 | 25 | 739.84 | 136 | 37.75 | 404.68 | 111.4 | 2.25 | 0.39 |
| 6 | 34.5 | 36 | 1190.25 | 207 | 44.13 | 164.27 | 92.72 | 0.25 | 0.28 |
| 7 | 50.7 | 49 | 2570.49 | 354.9 | 50.5 | 11.45 | 0.0383 | 0.25 | 0.0039 |
| 8 | 61.4 | 64 | 3769.96 | 491.2 | 56.88 | 198.34 | 20.44 | 2.25 | 0.0736 |
| 9 | 69.3 | 81 | 4802.49 | 623.7 | 63.25 | 483.27 | 36.56 | 6.25 | 0.0872 |
| 10 | 94.4 | 100 | 8911.36 | 944 | 69.63 | 2216.84 | 613.62 | 12.25 | 0.26 |
| 11 | 61.1 | 121 | 3733.21 | 672.1 | 76 | 189.98 | 222.11 | 20.25 | 0.24 |
| 12 | 78.2 | 144 | 6115.24 | 938.4 | 82.38 | 953.78 | 17.46 | 30.25 | 0.0534 |
| 78 | 567.8 | 650 | 33949.9 | 4602.3 | 567.8 | 7083.5 | 1272.21 | 143 | 2.41 |
Для наших данных система уравнений имеет вид:
12a 0 + 78a 1 = 567.8
78a 0 + 650a 1 = 4602.3
Из первого уравнения выражаем а 0 и подставим во второе уравнение
Получаем a 0 = 6.37, a 1 = 5.88
Примечание: значения столбца №6 y(t) рассчитываются на основе полученного уравнения тренда. Например, t = 1: y(1) = 6.37*1 + 5.88 = 12.26
Уравнение тренда
y = 6.37 t + 5.88Оценим качество уравнения тренда с помощью ошибки абсолютной аппроксимации.
![]()
Поскольку ошибка больше 15%, то данное уравнение не желательно использовать в качестве тренда.
Средние значения:
![]()
![]()
![]()
Дисперсия
![]()
Среднеквадратическое отклонение
Коэффициент эластичности
![]()
Коэффициент эластичности меньше 1. Следовательно, при изменении Х на 1%, Y изменится менее чем на 1%. Другими словами - влияние Х на Y не существенно.
Коэффициент детерминации

т.е. в 82.04 % случаев влияет на изменение данных. Другими словами - точность подбора уравнения тренда - высокая
2. Анализ точности определения оценок параметров уравнения тренда
.
Дисперсия ошибки уравнения.
где m = 1 - количество влияющих факторов в модели тренда.
Стандартная ошибка уравнения.
3. Проверка гипотез относительно коэффициентов линейного уравнения тренда
.
1) t-статистика. Критерий Стьюдента.
По таблице Стьюдента находим Tтабл
T табл (n-m-1;α/2) = (10;0.025) = 2.228
>
Статистическая значимость коэффициента a 0 подтверждается. Оценка параметра a 0 является значимой и тренд у временного ряда существует..
Статистическая значимость коэффициента a 1 не подтверждается.
Доверительный интервал для коэффициентов уравнения тренда
.
Определим доверительные интервалы коэффициентов тренда, которые с надежность 95% будут следующими:
(a 1 - t набл S a 1 ;a 1 + t набл S a 1)
(6.375 - 2.228*0.943; 6.375 + 2.228*0.943)
(4.27;8.48)
(a 0 - t набл S a 0 ;a 0 + t набл S a 0)
(5.88 - 2.228*6.942; 5.88 + 2.228*6.942)
(-9.59;21.35)
Так как точка 0 (ноль) лежит внутри доверительного интервала, то интервальная оценка коэффициента a 0 статистически незначима.
2) F-статистика. Критерий Фишера.

Fkp = 4.84
Поскольку F > Fkp, то коэффициент детерминации статистически значим
Проверка на наличие автокорреляции остатков
.
Важной предпосылкой построения качественной регрессионной модели по МНК является независимость значений случайных отклонений от значений отклонений во всех других наблюдениях. Это гарантирует отсутствие коррелированности между любыми отклонениями и, в частности, между соседними отклонениями.
Автокорреляция (последовательная корреляция)
определяется как корреляция между наблюдаемыми показателями, упорядоченными во времени (временные ряды) или в пространстве (перекрестные ряды). Автокорреляция остатков (отклонений) обычно встречается в регрессионном анализе при использовании данных временных рядов и очень редко при использовании перекрестных данных.
В экономических задачах значительно чаще встречается положительная автокорреляция
, нежели отрицательная автокорреляция
. В большинстве случаев положительная автокорреляция вызывается направленным постоянным воздействием некоторых неучтенных в модели факторов.
Отрицательная автокорреляция
фактически означает, что за положительным отклонением следует отрицательное и наоборот. Такая ситуация может иметь место, если ту же зависимость между спросом на прохладительные напитки и доходами рассматривать по сезонным данным (зима-лето).
Среди основных причин, вызывающих автокорреляцию
, можно выделить следующие:
1. Ошибки спецификации. Неучет в модели какой-либо важной объясняющей переменной либо неправильный выбор формы зависимости обычно приводят к системным отклонениям точек наблюдения от линии регрессии, что может обусловить автокорреляцию.
2. Инерция. Многие экономические показатели (инфляция, безработица, ВНП и т.д.) обладают определенной цикличностью, связанной с волнообразностью деловой активности. Поэтому изменение показателей происходит не мгновенно, а обладает определенной инертностью.
3. Эффект паутины. Во многих производственных и других сферах экономические показатели реагируют на изменение экономических условий с запаздыванием (временным лагом).
4. Сглаживание данных. Зачастую данные по некоторому продолжительному временному периоду получают усреднением данных по составляющим его интервалам. Это может привести к определенному сглаживанию колебаний, которые имелись внутри рассматриваемого периода, что в свою очередь может служить причиной автокорреляции.
Последствия автокорреляции схожи с последствиями гетероскедастичности
: выводы по t- и F-статистикам, определяющие значимость коэффициента регрессии и коэффициента детерминации, возможно, будут неверными.
Обнаружение автокорреляции
1. Графический метод
Есть ряд вариантов графического определения автокорреляции. Один из них увязывает отклонения e i с моментами их получения i. При этом по оси абсцисс откладывают либо время получения статистических данных, либо порядковый номер наблюдения, а по оси ординат – отклонения e i (либо оценки отклонений).
Естественно предположить, что если имеется определенная связь между отклонениями, то автокорреляция имеет место. Отсутствие зависимости скорее всего будет свидетельствовать об отсутствии автокорреляции.
Автокорреляция становится более наглядной, если построить график зависимости e i от e i-1
Критерий Дарбина-Уотсона
.
Этот критерий является наиболее известным для обнаружения автокорреляции.
При статистическом анализе уравнения регрессии на начальном этапе часто проверяют выполнимость одной предпосылки: условия статистической независимости отклонений между собой. При этом проверяется некоррелированность соседних величин e i .
| y | y(x) | e i = y-y(x) | e 2 | (e i - e i-1) 2 |
| 17.4 | 12.26 | 5.14 | 26.47 | 0 |
| 26.9 | 18.63 | 8.27 | 68.39 | 9.77 |
| 23 | 25 | -2 | 4.02 | 105.57 |
| 23.7 | 31.38 | -7.68 | 58.98 | 32.2 |
| 27.2 | 37.75 | -10.55 | 111.4 | 8.26 |
| 34.5 | 44.13 | -9.63 | 92.72 | 0.86 |
| 50.7 | 50.5 | 0.2 | 0.0384 | 96.53 |
| 61.4 | 56.88 | 4.52 | 20.44 | 18.71 |
| 69.3 | 63.25 | 6.05 | 36.56 | 2.33 |
| 94.4 | 69.63 | 24.77 | 613.62 | 350.63 |
| 61.1 | 76 | -14.9 | 222.11 | 1574.09 |
| 78.2 | 82.38 | -4.18 | 17.46 | 115.03 |
| 1272.21 | 2313.98 |
Для анализа коррелированности отклонений используют статистику Дарбина-Уотсона
:
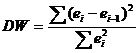
![]()
Критические значения d 1 и d 2 определяются на основе специальных таблиц для требуемого уровня значимости α, числа наблюдений n = 12 и количества объясняющих переменных m=1.
Автокорреляция отсутствует, если выполняется следующее условие:
d 1 < DW и d 2 < DW < 4 - d 2 .
Не обращаясь к таблицам, можно пользоваться приблизительным правилом и считать, что автокорреляция остатков отсутствует, если 1.5 < DW < 2.5. Поскольку 1.5 < 1.82 < 2.5, то автокорреляция остатков отсутствует
.
Для более надежного вывода целесообразно обращаться к табличным значениям.
По таблице Дарбина-Уотсона для n=12 и k=1 (уровень значимости 5%) находим: d 1 = 1.08; d 2 = 1.36.
Поскольку 1.08 < 1.82 и 1.36 < 1.82 < 4 - 1.36, то автокорреляция остатков отсутствует
.
Проверка наличия гетероскедастичности
.
1) Методом графического анализа остатков
.
В этом случае по оси абсцисс откладываются значения объясняющей переменной X, а по оси ординат либо отклонения e i , либо их квадраты e 2 i .
Если имеется определенная связь между отклонениями, то гетероскедастичность имеет место. Отсутствие зависимости скорее всего будет свидетельствовать об отсутствии гетероскедастичности.
2) При помощи теста ранговой корреляции Спирмена
.
Коэффициент ранговой корреляции Спирмена
.
Присвоим ранги признаку Y и фактору X. Найдем сумму разности квадратов d 2 .
По формуле вычислим коэффициент ранговой корреляции Спирмена.
![]()
| t | e i | ранг X, d x | ранг e i , d y | (d x - d y) 2 |
| 1 | -5.14 | 1 | 4 | 9 |
| 2 | -8.27 | 2 | 2 | 0 |
| 3 | 2 | 3 | 7 | 16 |
| 4 | 7.68 | 4 | 9 | 25 |
| 5 | 10.55 | 5 | 11 | 36 |
| 6 | 9.63 | 6 | 10 | 16 |
| 7 | -0.2 | 7 | 6 | 1 |
| 8 | -4.52 | 8 | 5 | 9 | t табл (n-m-1;α/2) = (10;0.05/2) = 2.228
Является тренд . Одним из наиболее популярных способов моделирования тенденции временного ряда является нахождение аналитической функции, характеризующей зависимость уровней ряда от времени. Этот способ называется аналитическим выравниванием временного ряда.
Зависимость показателя от времени может принимать разные формы, поэтому находят различные функции: линейную, гиперболу, экспоненту, степенную функцию, полиномы различных степеней. Временной ряд исследуют аналогично линейной регрессии.
Параметры любого тренда можно определить обычным методом наименьших квадратов, используя в качестве фактора время t = 1, 2,…, n, а в качестве зависимой переменной используют уровни временного ряда. Для нелинейных трендов сначала проводят процедуру линеаризации.
К числу наиболее распространенных способов определения типа тенденции относят качественный анализ изучаемого ряда , построение и анализ графика зависимости уровней ряда от времени, расчет основных показателей динамики. В этих же целях можно часто используют и .
Линейный тренд
Тип тенденции определяют путем сравнения коэффициентов автокорреляции первого порядка. Если временной ряд имеет линейный тренд, то его соседние уровни yt и yt-1 тесно коррелируют. В таком случае коэффициент автокорреляции первого порядка уровней исходного ряда должен быть максимальный. Если временной ряд содержит нелинейную тенденцию, то чем сильнее выделена нелинейная тенденция во временном ряду, тем в большей степени будут различаться значения указанных коэффициентов.
Выбор наилучшего уравнения в случае, если ряд содержит , можно осуществить перебором основных видов тренда, расчета по каждому уравнению коэффициента корреляции и выбора уравнения тренда с максимальным значением коэффициента.
Параметры тренда
Наиболее простую интерпретацию имеют параметры экспоненциального и линейного трендов.
Параметры линейного тренда интерпретируют так: а — исходный уровень временного ряда в момент времени t = 0; b - средний за период абсолютный прирост уровней рада.
Параметры экспоненциального тренда имеют такую интерпретацию. Параметр а - это исходный уровень временного ряда в момент времени t = 0. Величина exp(b) - это средний в расчете на единицу времени коэффициент роста уровней ряда.
По аналогии с линейной моделью расчетные значения уровней рада по экспоненциальному тренду можно определить путем подстановки в уравнение тренда значений времени t = 1,2,…, n, либо в соответствии с интерпретацией параметров экспоненциального тренда: каждый последующий уровень такого ряда есть произведение предыдущего уровня на соответствующий коэффициент роста
При наличии неявной нелинейной тенденции нужно дополнять описанные выше методы выбора лучшего уравнения тренда качественным анализом динамики изучаемого показателя, для того, чтобы избежать ошибок спецификации при выборе вида тренда. Качественный анализ предполагает изучение проблем возможного наличия в исследуемом ряду поворотных точек и изменения темпов прироста, начиная с определенного момента времени под влиянием ряда факторов, и т. д. В том случае если уравнение тренда выбрано неправильно при больших значениях t, результаты прогнозирования динамики временного ряда с использованием исследуемого уравнения будут недостоверными по причине ошибки спецификации.
Иллюстрация возможного появления ошибки спецификации приведем на рисунке
Если оптимальной формой тренда является парабола, в то время как на самом деле имеет место линейная тенденция, то при больших t парабола и линейная функция естественно будут по разному описывать тенденцию в уровнях ряда.
Статистические расчеты содержания влаги
контрольная работа
2. Уравнение тренда на основе линейной зависимости.
2.1. Основные элементы временного ряда.
Можно построить эконометрическую модель, используя два типа исходных данных:
Данные, характеризующие совокупность различных объектов в определённый момент времени.
Данные, характеризующие один объект за ряд последовательных моментов времени.
Модели, построенные по данным первого типа, называются пространственными. Модели, построенные на основе второго типа данных, называются временными рядами.
Временной ряд - это совокупность значений какого-либо показателя за несколько последовательных моментов или периодов времени. Каждый уровень временного ряда формируется под воздействием большого числа факторов, которые условно можно подразделить на три группы:
Факторы, формирующие тенденцию ряда.
Факторы, формирующие циклические колебания ряда.
Случайные факторы.
При различных сочетаниях в изучаемом явлении или процессе этих факторов зависимость уровней ряда от времени может принимать различные формы.
Во-первых, большинство временных рядов экономических показателей имеют тенденцию, характеризующую совокупное долговременное воздействие множества факторов на динамику изучаемого показателя. Очевидно, что эти факторы, взятые в отдельности, могут оказывать разнонаправленное воздействие на исследуемый показатель. Однако в совокупности они формируют его возрастающую или убывающую тенденцию. На рис. 1. показан временной ряд, содержащий возрастающую тенденцию.
Во-вторых, изучаемый показатель может быть подвержен циклическим колебаниям. Эти колебания могут носить сезонный характер, поскольку экономическая деятельность ряда отраслей экономики зависит от времени года. При наличии больших массивов данных за длительные промежутки времени можно выявить циклические колебания, связанные с общей динамикой конъюнктуры рынка, а также с фазой бизнес цикла, в которой находится экономика страны. На рис. 2. представлен временной ряд, содержащий только сезонную компоненту.
Некоторые временные ряды не содержат тенденции и циклической компоненты, а каждый следующий их уровень базируется как сумма среднего уровня ряда и некоторой случайной компоненты. Пример ряда, содержащего только случайную компоненту, приведён на рис. 3.
Очевидно, что реальные данные не следуют полностью из каких-либо описанных моделей. Чаще всего они содержат все три компоненты. Каждый их уровень формируется под воздействием тенденции, сезонных колебаний и случайной компоненты.
В большинстве случаев фактический уровень временного ряда можно представить как сумму или произведение трендовой, циклической и случайной компонент. Модель, в которой временной ряд представлен как сумма перечисленных компонент, называется аддитивной моделью. Модель, в которой временной ряд представлен как произведение перечисленных компонент, называется мультипликативной моделью.
2.2. Автокорреляция уровней временного ряда.
При наличии во временном ряде тенденции и циклических колебаний значения каждого последующего уровня ряда зависят от предыдущих. Корреляционную зависимость между последовательными уровнями временного ряда называют автокорреляцией. Количественно её можно измерить с помощью линейного коэффициента корреляции между уровнями исходного временного ряда и уровнями этого ряда, сдвинутыми во времени.
Одна из рабочих формул для расчёта коэффициента корреляции имеет вид:
r xy = (x j - x ) * (y j - y ) .
(x j -x) 2 * (y j -y) 2
В качестве переменной x мы рассмотрим ряд y 2 , y 3 , ... y t ; в качестве переменной y рассмотрим ряд y 1 , y 2 , ... y t -1 . Тогда данная формула примет вид:
r 1 = (y t - y 1 ) * (y t-1 - y 2 ) ; где y 1 = y t ; y 2 = y t-1 .
(y t -y 1) 2 * (y t-1 -y 2) 2 n - 1 n - 1
Эту величину называют коэффициентом автокорреляции уровней ряда первого порядка. Число периодов, по которым рассчитывается коэффициент автокорреляции, называют лагом. С увеличением лага число пар значений, по которым рассчитывается коэффициент автокорреляции, уменьшается.
Свойства коэффициента автокорреляции:
Во-первых, он строится по аналогии с линейным коэффициентом корреляции и таким образом характеризует тесноту только линейной связи текущего и предыдущего уровней ряда. Поэтому по коэффициенту автокорреляции можно судить о наличии линейной тенденции.
Во-вторых, по знаку коэффициента автокорреляции нельзя делать вывод о возрастающей или убывающей тенденции в уровнях ряда.
Последовательность коэффициентов автокорреляции уровней первого, второго, и т.д. порядков называют автокорреляционной функцией временного ряда. График зависимости её значений от величины лага называется коррелограммой. Анализ автокорреляционной функции и коррелограммы позволяет определить лаг, при котором автокорреляция наиболее высокая, а, следовательно, и лаг, при котором связь между текущим и предыдущим уровнями ряда наиболее тесная, т.е. при помощи анализа автокорреляционной функции и коррелограммы можно выявить структуру ряда.
Если наиболее высоким оказался коэффициент автокорреляции первого порядка, исследуемый ряд содержит только тенденцию. Если наиболее высоким оказался коэффициент автокорреляции порядка t, ряд содержит циклические колебания с периодичностью в t моментов времени. Если ни один из коэффициентов автокорреляции не является значимым, можно сделать вывод: либо ряд не содержит тенденции и циклических колебаний, либо ряд содержит сильную нелинейную тенденцию, для выявления которой нужно провести дополнительный анализ.
2.3. Моделирование тенденции временного ряда.
Одним из наиболее распространённых способов моделирования тенденции временного ряда является построение аналитической функции, характеризующей зависимость уровней ряда от времени, или тренда. Этот способ называют аналитическим выравниванием временного ряда.
Т.к. зависимость от времени может принимать разные формы, для её формализации можно использовать различные виды функции. Для построения трендов чаще всего применяются следующие функции:
Линейный тренд: y t = a + b*t ;
Гипербола:y t = a + b/t ;
Экспоненциальный тренд: y t = e a + b * t ;
Тренд в форме степенной функции: y t = a*t ;
Парабола: y t = a + b 1 *t + b 2 *t 2 + ... + b k *t k ;
Параметры каждого из этих трендов можно определить методом наименьших квадратов, используя в качестве независимой переменной время t = 1, 2, ... ,n , а в качестве зависимой переменной - фактические уровни временного ряда y t . Для нелинейных трендов предварительно проводят стандартную процедуру их линеаризации.
Существует несколько способов определения типа тенденции. К числу наиболее распространённых способов относятся качественный анализ изучаемого процесса, построение и визуальный анализ графика зависимости уровней ряда от времени, расчёт некоторых основных показателей динамики. В этих же целях можно использовать и коэффициенты автокорреляции уровней ряда. Тип тенденции можно определить путем сравнения коэффициентов автокорреляция первого порядка, рассчитанных по исходным и преобразованным уровням ряда. Если временной ряд имеет линейную тенденцию, то его соседние уровни y t и y t -1 тесно коррелируют. В этом случае коэффициент автокорреляции первого порядка уровней исходного ряда должен быть высоким. Если временной ряд содержит не6линейную тенденцию, например, в форме экспоненты, то коэффициент автокорреляции первого порядка по логарифмам уровней исходного ряда будет выше, чем соответствующий коэффициент, рассчитанный по уровням ряда. Чем сильнее выражена нелинейная тенденция в изучаемом временном ряде, тем в большей степени будут различаться значения указанных коэффициентов.
Выбор наилучшего уравнения в случае, если ряд содержит нелинейную тенденцию, можно осуществить путем перебора основных форм тренда, расчета по каждому уравнению скорректированного коэффициента детерминации R и выбора уравнения тренда с максимальным значением скорректированного коэффициента детерминации.
Высокие значения коэффициентов автокорреляции первого, второго и третьего порядков свидетельствуют о том, что ряд содержит тенденцию. Приблизительно равные значения коэффициентов автокорреляции по уровням этого ряда и по логарифмам уровней позволяют сделать следующий вывод: если ряд содержит нелинейную тенденцию, то она выражена в неявной форме. Поэтому для моделирования его тенденции в равной мере целесообразно использовать и линейную, и нелинейную функции, например степенной или экспоненциальный тренд. Для выявления наилучшего уравнения тренда необходимо определить параметры основных видов трендов.
Наиболее простую экономическую интерпретацию имеют параметры линейного и экспоненциального трендов. Параметры линейного тренда:
a - начальный уровень временного ряда в момент времени t = 0;
b - средний за период абсолютный прирост уровней ряда.
Расчётные по линейному тренду значения уровней временного ряда определяются двумя способами. Во-первых, можно последовательно подставлять в найденное уравнение тренда значения t = 1, 2, ..., n. Во-вторых, в соответствии с интерпретацией параметров линейного тренда каждый последующий уровень ряда есть сумма предыдущего уровня и среднего цепного абсолютного прироста.
Задача №1
Десять человек различного возраста имеют следующие параметры:
1. Определить результативный признак.
Рассчитаем зависимость роста от возраста:
Фактор (X): возраст.
Результативный признак (Y): рост.
a*x + b*x 2 = x*y
10*a + 248*b = 1812
248*a + 6492*b = 45023
a = 1812 - 248*b => 1812 - 248*b *248 + 6492*b = 45023
r = x*y - ( x* y)/n = 45023 - (248*1812)/10 =>
(x 2 - (x) 2 /n)*(y 2 - (y) 2 /n) (6492 - 248 2 /10)*(328444 - 1812 2 /10)
r = 0.44 - прямая умеренная связь
r 2 = 0.19 - рост на 19% зависит от возраста
Тест Фишера:
F cp = r 2 * (n - 2)
F cp = 0.19 * (10 - 2) = 1.78
F табл = 5.32
F cp < F табл =>
Рассчитаем зависимость веса от возраста:
Фактор (X): возраст.
Определим параметры линейной функции с помощью системы уравнений:
a*x + b*x 2 = x*y
10*a + 248*b = 753
248*a + 6492*b = 18856
a = 753 - 248*b => 1812 - 248*b *248 + 6492*b = 18856
r = x*y - ( x* y)/n = 18856 - (248*753)/10 =>
(x 2 - (x) 2 /n)*(y 2 - (y) 2 /n) (6492 - 248 2 /10)*(56967 - 753 2 /10)
r = 0.6 - заметная прямая связь
r 2 = 0.36 - вес на 36% зависит от возраста
Тест Фишера:
F cp = r 2 * (n - 2)
F cp = 0.36 * (10 - 2) = 4.5
F табл = 5.32
F cp < F табл => нулевая гипотеза подтвердилась, уравнение статистически незначимо.
Рассчитаем зависимость веса от роста:
Фактор (X): рост.
Результативный признак (Y): вес.
Определим параметры линейной функции с помощью системы уравнений:
a*x + b*x 2 = x*y
10*a + 1812*b = 753
1812*a + 328444*b = 136562
a = 753 - 1812*b => 753 - 1812*b *1812 + 328444*b = 136562
r = x*y - ( x* y)/n = 136562 - (1812*753)/10 =>
(x 2 - (x) 2 /n)*(y 2 - (y) 2 /n) (328444 - 1812 2 /10)*(56967 - 753 2 /10)
r = 0.69 - заметная прямая связь
r 2 = 0.47 - вес на 47% зависит от роста
x = 1812/10 = 181.2
Тест Фишера:
F cp = r 2 * (n - 2)
F cp = 0.47 * (10 - 2) = 7.1
F табл = 5.32
F cp > F табл => нулевая гипотеза не подтвердилась, уравнение имеет экономический смысл.
Тест Стьюдента:
Рассчитаем случайные ошибки:
.
m a = (y - y x ) 2 * x 2 .
n - 2 n*(x -x) 2
m b = (y - y x ) 2 / (n - 2)
m r = 1 - r 2
m a = 138.19 * 328444 = 72
m b = 138.19 / (10 - 2) = 1
m r = 1 - 0.47 = 0.26
t a = a/m a = 120/72 = 1.67
t b = b/m b = 1.08/1 = 1.08
t r = r/m r = 0.69/0.26 = 2.65
t табл = 2.3
Для расчёта доверительного интервала рассчитаем предельную ошибку:
a = t табл - t a = 2.3 - 1.67 = 0.63
b = t табл - t b = 2.3 - 1.08 = 1.22
r = t табл - t r = 2.3 - 2.65 = -0.35
Рассчитаем доверительные интервалы:
a = a a = -121.03 119.77
b = b b = -0.14 2.3
r = r r = 0.34 1.04
Задача №2
При контрольной выборочной проверке процента влажности почвы фермерских хозяйств региона получены следующие данные:
1. С вероятностью 0.95 и 0.99 установить предел, в котором находится средний процент содержания влаги.
2. Сделать выводы.
Генеральная средняя: x = x = 31.1 = 3.8875
Генеральная дисперсия: 2 = (x - x ) 2 = 1.8875 = 0.1261
n 8 .
Средняя квадратическая стандартная ошибка: x = 2 = 0.1261 = 0.126
Предельная ошибка выборки: x = t* x
Из таблицы значений t-критерия Стьюдента:
Для вероятности 0.95, предельная ошибка выборки:
x = 2.4469*0.126 = 0.308
Для вероятности 0.99, предельная ошибка выборки:
x = 3.7074*0.126 = 0.467
Доверительные интервалы:
Предел среднего процента содержания влаги с вероятностью 0.95:
Верхний центральный показатель некоторой линейной системы
Пусть дана система (2) и - ее решение. Рассмотрим семейство функций, Определение 5 : Функция R (t) называется верхней для системы (2), если она ограничена, измерима и осуществляет оценку, Где - норма матрицы Коши линейной системы...
Дифференциальное исчисление
Исходя из определения производной сформулируем следующее правило нахождения производной функции в точке: Чтобы вычислить производную функции f(x) в точке x0 нужно: 1) Найти f(x) - f(x0); 2) составить разностное отношение; 3) вычислить предел...
Дифференциальное исчисление
Исходя из определения производной...
Инвариантные подгруппы бипримарных групп
В заметке (1) исправлена ошибка, допущенная Бернсайдом в работе (2). А именно в (3) доказано, что группа порядка, где и - различные простые числа и, либо обладает характеристической -подгруппой порядка...
Использование современной компьютерной техники и программного обеспечения для решения прикладной задачи из инженерно-буровой практики
Зная значения коэффициентов а0, а1 и а2 можно найти значений y` по формуле, в нашем случае. Различие между экспериментальными и теоретическими данными невелико. Полученные данные позволяет нам найти зависимость, 5...
Линейная сложность циклотомических последовательностей
Пусть последовательность четвертого порядка, то есть, тогда, согласно лемме 1.1, она формируется по правилу: (2.1) Заметим, что правило (2.1) задает последовательность только тогда, когда...
Математическая модель цифрового устройства игры "Крестики-нолики" с человеком
Игровое поле игры в крестики-нолики может быть представлено в виде сетки, состоящей из строк и столбцов. Каждый элемент сетки может находиться в трех состояниях: пустое (начальное), отмечено крестиком, отмечено ноликом...
Методы отсечения
Среди совокупности п неделимых предметов, каждый i-и (i=1,2,…, п) из которых обладает по i-й характеристике показателем и полезностью найти такой набор, который позволяет максимизировать эффективность использования ресурсов величины...
Приближенное решение алгебраических и трансцендентных уравнений. Метод Ньютона
Информация о предыдущих приближениях корня используется для нахождения последующих приближений не только в методе касательных. В качестве примера другого такого метода мы приведём метод...
Статистические расчеты содержания влаги
Практические задачи: 1. Десять человек различного возраста имеют следующие параметры: Возраст, лет 18 20 21 22 22 24 25 26 31 39 Рост, см 174 183 182 180 178 179 185 185 184 182 Вес, кг 65 73 69 74 77 75 78 84 79 79 1...



